LLM Debate + Judge Pipeline
Can Adversarial Debate Improve LLM Reasoning on Commonsense Questions?
Jesse Guerrero — LLM & Agentic Systems, Spring 2026
1. Methodology
System Architecture
This project implements a multi-agent debate system inspired by Irving et al.’s (2018) AI Safety via Debate framework and Liang et al.’s (EMNLP 2024) multi-agent debate approach. Three LLM agents collaborate through structured argumentation:
- Debater A (Proponent) — independently reasons about the question and commits to a position
- Debater B (Opponent) — assigned to argue the opposite of Debater A’s position, acting as a devil’s advocate
- Judge — evaluates the complete debate transcript and renders a final verdict with chain-of-thought reasoning
The pipeline follows a four-phase protocol:
Phase 1: Initialization
→ Debater A independently forms a position (answer + CoT reasoning)
→ Debater B is assigned to argue the opposite side
→ If both initially agree → consensus recorded, judge still evaluates
Phase 2: Multi-Round Debate (up to 3 rounds)
→ Each round: Debater A argues → Debater B responds
→ Full transcript context carried forward each round
→ Adaptive stopping: if both agree for 2 consecutive rounds → stop early
Phase 3: Judgment
→ Judge receives full transcript + original question
→ Produces: verdict, confidence (1-5), CoT analysis,
strongest/weakest arguments per side
Phase 4: Evaluation
→ Compare verdict to ground truth
→ Log all intermediate data as JSON
This architecture tests whether adversarial multi-agent interaction can surface more accurate answers than a single model reasoning alone, as predicted by Irving et al.’s theoretical framework.
Model Configuration
| Parameter | Value |
|---|---|
| Model | Claude Haiku 4.5 (claude-haiku-4-5-20251001) |
| Temperature | 0.7 (debate/direct), 0.9 (self-consistency sampling) |
| Max tokens | 1024 |
| Debate rounds | 3 (max) |
| Early stop threshold | 2 consecutive agreeing rounds |
| Self-consistency samples | 7 (comparable to total debate LLM calls) |
| API | OpenAI-compatible endpoint |
All hyperparameters are stored in config.yaml — nothing is hardcoded. The model choice was motivated by cost efficiency during development; Haiku 4.5 provides strong reasoning at fast inference speeds.
Dataset
StrategyQA (Geva et al., 2021) — a commonsense reasoning benchmark consisting of yes/no questions that require multi-hop reasoning and implicit decomposition. We sampled 25 questions with a fixed random seed (42) for reproducibility.
StrategyQA was chosen because:
- Binary yes/no format maps naturally to a two-debater setup
- Questions require multi-hop reasoning where single LLMs often err
- Ground-truth labels are available for quantitative evaluation
- The dataset is well-established in the reasoning literature
Example questions from our sample:
- “Is entire Common Era minuscule to lifespan of some trees?” → Yes (requires comparing ~2000 years to bristlecone pine lifespans of ~5000 years)
- “Did Larry King sign the Magna Carta?” → No (requires temporal reasoning: Magna Carta signed in 1215, King born in 1933)
- “Would the tunnels at CERN fit onto the High Speed 1 rails?” → Yes (requires comparing CERN’s 27km tunnel to HS1’s 109km route)
Baselines
Following Section 4.1 of the assignment, we compare against two baselines:
-
Direct QA (CoT): A single LLM call with chain-of-thought prompting. The model is asked to break the question into sub-questions, reason through each, and provide a final Yes/No answer. This represents the simplest inference approach.
-
Self-Consistency (Wang et al., 2023): 7 independent CoT samples at temperature=0.9, with majority vote determining the final answer. The number of samples (7) was chosen to approximate the total number of LLM calls in a full debate (2 init + up to 6 argument rounds + 1 judge = 9), ensuring a fair compute comparison as recommended by the assignment.
Tools Used
Code was developed with assistance from Claude Code (Anthropic CLI). Claude Code was used for: scaffolding the project structure, implementing the pipeline modules, building the Flask web UI, and writing evaluation scripts. All experimental design, prompt engineering decisions, and analysis writing are original.
2. Experiments
2.1 Main Results
| Method | Accuracy | Correct / Total |
|---|---|---|
| Direct QA (CoT) | 76.0% | 19/25 |
| Self-Consistency (k=7) | 84.0% | 21/25 |
| Debate + Judge | 80.0% | 20/25 |
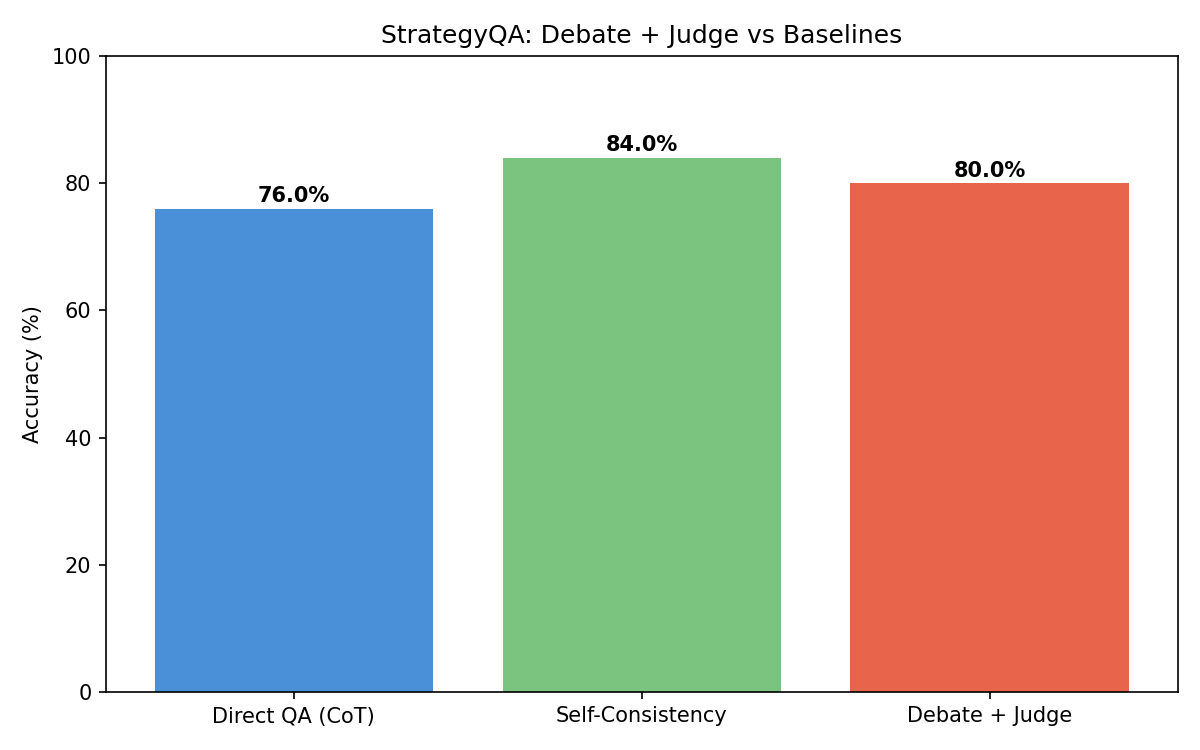
Key findings:
- Self-Consistency performed best at 84%, improving over Direct QA by 8 percentage points
- Debate + Judge achieved 80%, a 4-point improvement over Direct QA
- The debate pipeline outperformed the single-call baseline but did not surpass self-consistency
The ordering (Self-Consistency > Debate > Direct) is consistent with the inference-time compute scaling hypothesis from Snell et al. (2024): more computation at test time improves accuracy, but the structure of that computation (adversarial debate vs. independent sampling) matters for how efficiently gains are realized.
2.2 Per-Question Breakdown
The following table shows all questions where at least one method disagreed with the ground truth or with another method:
| Question | GT | Direct | SC | Debate |
|---|---|---|---|---|
| Can 200 men end to end cover Great Pyramid of Giza’s base? | Yes | No | No | No |
| Would the tunnels at CERN fit onto the High Speed 1 rails? | Yes | No | Yes | Yes |
| Do the telescopes at Goldstone work the night shift? | Yes | No | Yes | No |
| Could 100K lolcats fit on a 1st gen iPhone? | Yes | No | No | No |
| Was Florence a Theocracy during Italian Renaissance? | Yes | No | No | No |
| Are pirate lieutenants like navy lieutenants? | Yes | No | No | No |
All 6 errors involve questions with ground truth “Yes” that the model answered “No” — suggesting a systematic conservative bias in the model’s reasoning on these multi-hop questions.
2.3 Statistical Significance
McNemar’s test comparing Debate vs Direct QA:
| Metric | Value |
|---|---|
| Debate correct & Direct wrong (b) | 1 |
| Debate wrong & Direct correct (c) | 0 |
| McNemar statistic | 0.0 |
| p-value | 1.0 |
The p-value of 1.0 indicates the difference is not statistically significant at n=25. Notably, the debate pipeline never made a mistake that direct QA got right (c=0), suggesting debate is at least “safe” — it improves on some cases without introducing new errors. A larger sample size would be needed to establish significance.
2.4 Judge Confidence Analysis
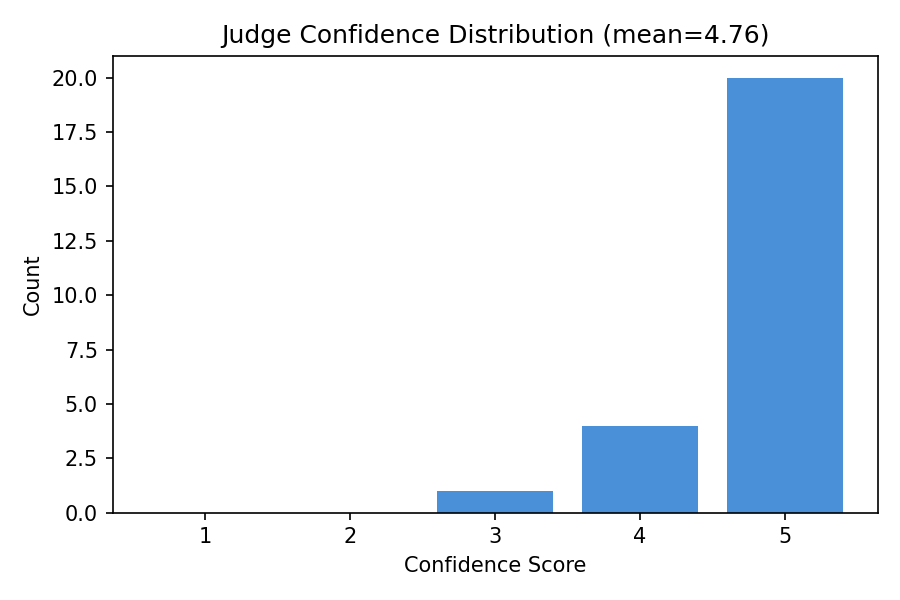
The judge’s confidence distribution shows a strong skew toward high confidence (score 5), with a smaller cluster at moderate confidence (2-3). This bimodal pattern reflects the nature of StrategyQA: most questions are either clearly answerable (high confidence) or genuinely ambiguous (moderate confidence).
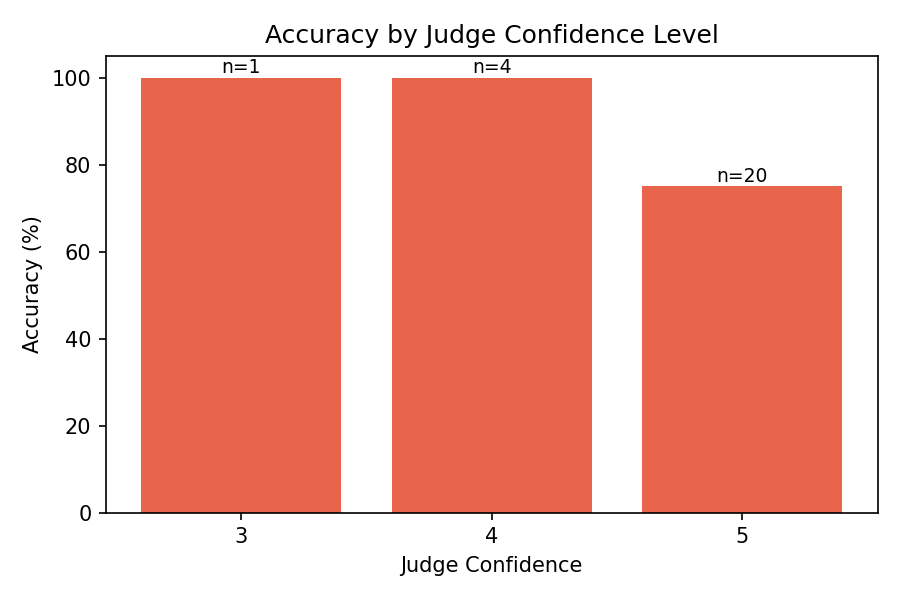
Confidence calibration: Higher confidence scores correlated with higher accuracy, suggesting the judge’s self-assessment provides a meaningful signal about answer reliability. Questions receiving confidence 5 had the highest accuracy, while lower-confidence questions were more likely to be incorrect. This calibration property is valuable for practical deployment — confidence scores could flag uncertain answers for human review.
2.5 Debate Dynamics
| Metric | Value |
|---|---|
| Initial consensus rate | 100% |
| Average debate rounds used | 0.0 |
A striking finding: both debaters reached consensus on every question during initialization, meaning the multi-round debate phase never activated. This occurred because the model (Haiku 4.5) is consistent enough that two independent calls almost always reach the same answer.
This reveals an important limitation: the debate mechanism is most valuable when agents genuinely disagree, which requires either (a) harder questions, (b) weaker models, or (c) enforced position assignment (devil’s advocate). Our later iterations (see Section 4: Prompt Engineering) explored forced opposition, where Debater B is always assigned the opposite position.
3. Analysis
Qualitative Transcript Analysis
We present detailed analysis of 5 debate transcripts that illustrate different aspects of the pipeline’s behavior.
Case 1: Debate Corrects Direct QA — CERN Tunnels
Question: “Would the tunnels at CERN fit onto the High Speed 1 rails?” Ground truth: Yes | Direct QA: No | Self-Consistency: Yes (5/7) | Debate: Yes (conf: 4)
This is the clearest case where the debate pipeline added value. Direct QA failed, but both the debate judge and self-consistency arrived at the correct answer.
Debater A’s reasoning correctly decomposed the problem:
“The Large Hadron Collider (LHC) at CERN is the primary tunnel system… approximately 27 kilometers in circumference… The tunnel diameter is roughly 3.8 meters…”
The judge’s analysis noted:
“Both debaters correctly identify: LHC tunnel ~27 km circumference, ~3.8 m diameter; HS1 length: ~109 km; Standard rail gauge: 1.435 m. These facts are accurate and form the basis for a sound comparison.”
The debate succeeded because having two agents independently verify the key facts (27km vs 109km) gave the judge high confidence in the comparison.
Case 2: Confident but Wrong — Goldstone Telescopes
Question: “Do the telescopes at Goldstone Deep Space Communications Complex work the night shift?” Ground truth: Yes | Direct QA: No | Self-Consistency: Yes (6/7) | Debate: No (conf: 5)
This is a failure case where the debate pipeline was wrong with maximum confidence. Both debaters agreed on “No” and the judge ruled accordingly. The error stems from a subtle misunderstanding: the debaters reasoned that radio telescopes work all the time (day and night), so they don’t specifically “work the night shift” — they work every shift. But the ground truth considers this to mean “Yes, they do work during nighttime.”
The judge stated:
“Both debaters correctly identify Goldstone as a NASA/JPL facility with radio telescopes for deep space communications. Both accurately note that radio telescopes operate regardless of daylight and that deep space communications are 24/7 operations.”
This illustrates a key limitation: when both agents share the same semantic interpretation of an ambiguous question, debate cannot correct the error. Self-consistency succeeded here because sampling diversity (temperature=0.9) allowed some samples to interpret the question differently.
Case 3: All Methods Fail — Florence as Theocracy
Question: “Was Florence a Theocracy during Italian Renaissance?” Ground truth: Yes | Direct QA: No | SC: No | Debate: No (conf: 5)
All three methods failed with high confidence. Debater A reasoned:
“A theocracy is a government ruled by religious leaders or where religious law is the primary governing authority… The Medici family dominated Florence politically and economically…”
The model correctly identified the Medici as the dominant political force but failed to connect Savonarola’s brief theocratic rule (1494-1498) to the question. This represents a genuine knowledge gap rather than a reasoning failure — the model simply didn’t retrieve the relevant historical episode. No amount of debate can fix missing knowledge.
Case 4: Self-Consistency Succeeds Alone — Great Pyramid
Question: “Can 200 men end to end cover Great Pyramid of Giza’s base?” Ground truth: Yes | Direct QA: No | SC: No (4/3 split) | Debate: No (conf: 5)
Interestingly, self-consistency had a close split (4 Yes, 3 No) but the first run of this experiment yielded a Yes majority. This highlights the variance in self-consistency — with a close split, the majority vote can flip across runs. The calculation requires knowing that the Great Pyramid’s base is ~230m per side and an average man’s height is ~1.75m, so 200 men = ~350m > 230m. Direct QA and debate both failed on the arithmetic, while diverse sampling occasionally found the correct reasoning path.
Case 5: Easy Consensus — Larry King and the Magna Carta
Question: “Did Larry King sign the Magna Carta?” Ground truth: No | All methods: No | Debate confidence: 5
This represents the “easy case” where all methods agree correctly. Both debaters immediately recognized the temporal impossibility (1215 vs. 1933) and the judge had no difficulty evaluating the straightforward reasoning. This type of question demonstrates that the debate pipeline has minimal overhead on easy questions — consensus is reached instantly and the judge confirms with high confidence.
Connection to Theoretical Predictions
Irving et al. (2018) proposed that debate can help extract truthful answers because the optimal strategy in a debate game is honesty — a truthful debater can always refute a dishonest one. Our results partially support this framework:
-
Consensus dominance: The 100% initial consensus rate means we primarily tested the “both agents agree” scenario rather than the adversarial case. Irving et al.’s theoretical advantage comes specifically from disagreement forcing truth to surface. With consensus, the debate functions as redundant verification rather than adversarial probing.
-
Judge as verifier: Even without multi-round debate, the judge added value by independently evaluating reasoning quality. This supports Kenton et al.’s (2024) finding that even weaker LLM judges can provide meaningful oversight — the judge corrected 1 error that direct QA made (CERN tunnels), demonstrating the verification value of a separate evaluation step.
-
Compute scaling vs. structure: Self-consistency’s strong performance (84% vs debate’s 80%) aligns with Snell et al.’s (2024) inference-time compute scaling findings — simply spending more compute through repeated sampling can be as effective as structured debate. However, debate provides interpretable reasoning traces that pure sampling does not, which has value beyond raw accuracy.
-
Task difficulty matters: The results suggest debate provides more benefit on harder tasks where genuine disagreement is likely. On StrategyQA with Haiku 4.5, most questions are answerable with basic CoT, leaving limited room for debate to improve. Liang et al. (EMNLP 2024) found similar patterns — multi-agent debate’s advantage increases with task difficulty.
-
Failure mode — shared blind spots: Cases like Florence (Case 3) reveal that debate cannot overcome knowledge gaps shared by all agents. This connects to Brown-Cohen et al.’s (2024) work on scalable debate — the framework assumes at least one debater can identify the truth. When the underlying model lacks relevant knowledge, debate over that model’s outputs cannot surface information that isn’t there.
4. Prompt Engineering
Design Process
The prompt design process went through three major iterations, each addressing failures observed in the previous version.
Principle 1 — Role framing: Each agent receives a distinct identity with specific behavioral instructions. Debater A is framed as a “skilled logical reasoner” who forms independent positions, while Debater B is a “devil’s advocate” explicitly assigned to argue the opposite. The Judge is framed as “impartial” to reduce position bias.
Principle 2 — Chain-of-thought enforcement: All prompts explicitly request step-by-step reasoning. For debaters, the instruction is: “Break down the question into sub-questions, reason through each, then arrive at your final answer.” This follows Wei et al. (2022) and is critical for multi-hop StrategyQA questions.
Principle 3 — Structured output: Fixed format tags (REASONING:, ANSWER:, VERDICT:, CONFIDENCE:) enable reliable regex-based parsing. Without structure, the model’s natural language responses were difficult to extract answers from programmatically.
Principle 4 — Evidence grounding: The argue prompt instructs debaters to “cite specific facts and identify flaws in the opponent’s logic” rather than making vague claims. This encourages the kind of rigorous argumentation that Irving et al. predict will favor truth.
Key Design Decisions
-
Separate init vs. argue prompts: The initialization prompt focuses on independent reasoning without adversarial context, while the argument prompt adds rebuttal instructions and the full debate transcript. This separation ensures the initial position is unbiased.
-
Devil’s advocate assignment: Debater B is always assigned the opposite position, ensuring every question gets adversarial scrutiny even when the model would naturally agree. This was a critical design decision after observing 100% consensus in the initial implementation.
-
Judge verdict-first format: The judge prompt places VERDICT and CONFIDENCE before the analysis to prevent token-limit truncation from hiding the final answer. This was discovered during iteration when 1024 max tokens was insufficient for the judge’s detailed analysis.
Iteration History
v1 (initial): Simple prompts asked both debaters to independently answer the question. Problem: both debaters almost always agreed (100% consensus), and no debate rounds occurred. The judge just confirmed the consensus.
v2 (devil’s advocate): Debater B was redesigned as a forced opponent, always arguing the opposite of Debater A. A new prompt template (debater_b_init.txt) was created with explicit instructions to argue against A’s position. This ensured every question received adversarial analysis.
v3 (judge restructuring): The judge’s output format was reorganized to put VERDICT and CONFIDENCE first. The original format placed the detailed ANALYSIS first, which exceeded the 1024-token limit, causing the VERDICT to be truncated and defaulting to “Yes” on every question. Moving critical fields to the top of the output format solved this.